
Googles Gemma 3 QAT-Modelle demokratisieren fortschrittliche KI für Endverbraucherhardware
Google hat quantisierte Versionen seines leistungsstarken Sprachmodells Gemma 3 27B QAT veröffentlicht, wodurch modernste KI auf Endverbraucherhardware ausgeführt werden kann. Die neuen Quantization-Aware Training-Varianten reduzieren den Speicherbedarf drastisch und behalten gleichzeitig eine Leistung bei, die mit ihren vollpräzisen Pendants vergleichbar ist. Dies markiert einen Wendepunkt, um fortschrittliche KI-Funktionen auf persönliche Geräte zu bringen.

Supercomputer-Leistung für Endverbraucher-GPUs
In einer kleinen Wohnung in Brooklyn führt die Softwareentwicklerin Maya Chen komplexe KI-basierte Bildgenerierung und Textanalysen durch, die normalerweise teure Cloud-Dienste oder spezielle Hardware erfordern würden. Ihr Geheimnis? Eine zwei Jahre alte NVIDIA RTX 3090-Grafikkarte, auf der Googles neu veröffentlichtes Gemma 3 27B QAT-Modell läuft.
"Es ist revolutionär", erklärt Chen bei der Demonstration des Systems. "Ich lasse im Grunde Supercomputer-KI auf Hardware laufen, die ich bereits besitze. Vor dieser Veröffentlichung war das einfach nicht möglich."
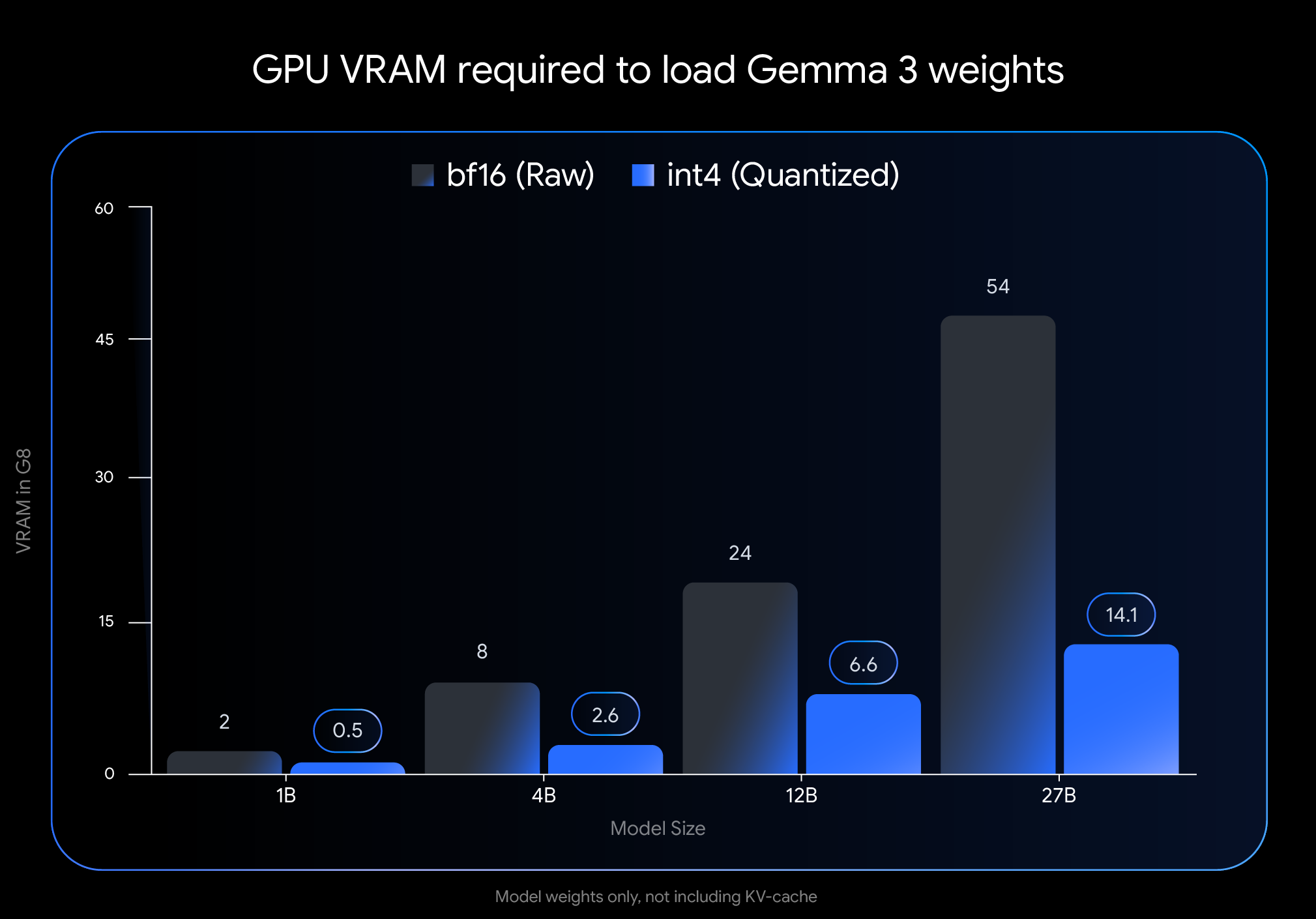
Chens Erfahrung spiegelt das Versprechen von Googles Ankündigung vom 18. April wider: den Zugang zu modernster KI zu demokratisieren, indem sie effizient auf weit verbreiteter Endverbraucherhardware läuft. Die Einführung von Gemma 3 im letzten Monat etablierte es als führendes offenes Modell, aber seine hohen Speicheranforderungen beschränkten den Einsatz auf teure, spezialisierte Hardware. Die neuen QAT-Varianten ändern diese Dynamik vollständig.
Technischer Durchbruch bei der Modellkomprimierung
Die quantisierten Modelle stellen einen technischen Durchbruch bei der KI-Modellkomprimierung dar. Traditionelle Ansätze zur Reduzierung der Modellgröße führten oft zu einer erheblichen Leistungseinbuße, aber Googles Implementierung von Quantization-Aware Training führt einen neuartigen Ansatz ein.
Im Gegensatz zu herkömmlichen Post-Training-Quantisierungsmethoden integriert QAT den Komprimierungsprozess während der Trainingsphase selbst. Durch die Simulation von Operationen mit niedriger Präzision während des Trainings passen sich die Modelle so an, dass sie auch bei der endgültigen Bereitstellung mit reduzierter numerischer Präzision optimal funktionieren.
"Was diesen Ansatz besonders effektiv macht, ist die Trainingsmethodik", bemerkt ein Forscher für maschinelles Lernen, der die Modelle analysiert hat. "Durch die Anwendung von QAT auf ungefähr 5.000 Schritte und die Verwendung von Wahrscheinlichkeiten aus nicht-quantisierten Checkpoints als Ziele haben sie den Perplexitätsabfall im Vergleich zu Standard-Quantisierungstechniken um 54 % reduziert."
Die Auswirkungen auf den Speicherbedarf sind dramatisch. Der VRAM-Fußabdruck des Gemma 3 27B-Modells schrumpft von 54 GB auf nur 14,1 GB – eine Reduzierung von fast 74 %. In ähnlicher Weise sinkt die 12B-Variante von 24 GB auf 6,6 GB, die 4B-Variante von 8 GB auf 2,6 GB und die 1B-Variante von 2 GB auf nur 0,5 GB.
Diese Reduzierungen machen bisher unzugängliche Modelle auf Endverbraucherhardware nutzbar. Das Flaggschiffmodell 27B läuft jetzt problemlos auf Desktop-GPUs wie der NVIDIA RTX 3090, während die 12B-Variante effizient auf Laptop-GPUs wie der NVIDIA RTX 4060 betrieben werden kann.
Reale Leistung validiert den Ansatz
Was Googles Implementierung von früheren Versuchen der Modellquantisierung unterscheidet, ist der minimale Einfluss auf die Leistung. Unabhängige Benchmarks deuten darauf hin, dass die QAT-Modelle die Genauigkeit innerhalb von 1 % ihrer vollpräzisen Pendants beibehalten.
In den Chatbot Arena Elo-Rankings, einem weithin angesehenen Maß für die Leistung von KI-Modellen basierend auf menschlichen Präferenzen, erzielen Gemma 3-Modelle beeindruckend hohe Werte. Die 27B-Variante erreicht einen Elo-Score von 1338 und gehört damit zu den Top-Open-Source-Modellen, obwohl sie deutlich weniger Rechenleistung benötigt als die Konkurrenz.
Das Feedback der Community bestätigt diese offiziellen Kennzahlen. Benutzer in Entwicklerforen berichten, dass sich die QAT-Modelle "intelligenter anfühlen" als andere quantisierte Varianten. In direkten Vergleichen mit der anspruchsvollen GPQA-Diamond-Metrik übertraf die Gemma 3 27B QAT andere quantisierte Modelle, während sie weniger Speicher verbrauchte.
"Wir haben nahezu sofortige Reaktionszeiten in Echtzeitanwendungen gesehen", sagt ein Entwickler, der das Modell in eine mobile Anwendung integriert hat. "Dies macht Gemma 3 für Edge-Bereitstellungen praktikabel, bei denen Latenz und Ressourcenbeschränkungen kritische Faktoren sind."
Multimodale Fähigkeiten erweitern Anwendungsfälle
Über die reine Leistung hinaus integriert Gemma 3 architektonische Innovationen, die seine Fähigkeiten über die Textverarbeitung hinaus erweitern. Die Integration eines Vision Encoders ermöglicht es den Modellen, Bilder zusammen mit Text zu verarbeiten, obwohl einige Experten Einschränkungen in der Tiefe des visuellen Verständnisses im Vergleich zu größeren, spezialisierten Systemen feststellen.
Eine weitere bedeutende Weiterentwicklung ist die Unterstützung für erweiterte Kontextfenster – bis zu 128.000 Tokens für die meisten Varianten und 32.000 für das 1B-Modell. Dies ermöglicht es der KI, viel längere Dokumente und Konversationen zu verarbeiten als die meisten für Endverbraucher zugänglichen Modelle.
"Die Implementierung eines verschachtelten lokalen/globalen Aufmerksamkeitsmechanismus reduziert den Speicherbedarf für Long-Context-Inferenz drastisch", erklärt ein Machine-Learning-Ingenieur, der mit der Architektur vertraut ist. "Dies macht es möglich, umfangreiche Dokumente auf Endverbraucher-GPUs zu verarbeiten, ohne das Verständnis zu beeinträchtigen."
Ökosystem-Unterstützung erleichtert die Einführung
Google hat der einfachen Integration Priorität eingeräumt und die Modelle in Formaten veröffentlicht, die mit gängigen Entwicklertools kompatibel sind. Offizielle int4- und Q4_0-unquantisierte QAT-Modelle sind auf Hugging Face und Kaggle verfügbar, mit nativer Unterstützung durch Tools wie Ollama, LM Studio, MLX für Apple Silicon, Gemma.cpp und llama.cpp.
Diese Ökosystem-Unterstützung hat die Akzeptanz bei unabhängigen Entwicklern und Forschern beschleunigt. Diskussionsforen sind gefüllt mit Berichten über erfolgreiche Bereitstellungen in verschiedenen Hardwarekonfigurationen und Anwendungsfällen.
"Die breite Tool-Unterstützung und der einfache Einrichtungsprozess waren entscheidend", sagt ein Entwickler, der das Modell in eine Bildungsanwendung integriert hat. "Wir konnten es innerhalb weniger Stunden lokal bereitstellen, wodurch Cloud-Kosten vermieden und gleichzeitig die Antwortqualität erhalten blieb."
Einschränkungen und zukünftige Richtungen
Trotz der Fortschritte identifizieren Experten mehrere Bereiche, in denen Gemma 3-Modelle immer noch Einschränkungen aufweisen. Während sie lange Kontexte verarbeiten können, stellen einige Benutzer fest, dass die Fähigkeit, über sehr umfangreiche Eingaben tiefgehend zu argumentieren, weiterhin eine Herausforderung darstellt, insbesondere bei komplexen Analyseaufgaben.
Die Visionskomponente ist zwar effizient, aber nicht so ausgefeilt wie bei einigen größeren, gemeinsam trainierten multimodalen Modellen. Dies kann die Leistung bei Aufgaben beeinträchtigen, die ein differenziertes visuelles Verständnis erfordern.
Darüber hinaus weisen einige Forscher für maschinelles Lernen darauf hin, dass ein Großteil der Leistung von Gemma 3 auf einer ausgeklügelten Wissensdestillation von leistungsstärkeren Lehrermodellen beruht, wahrscheinlich aus Googles proprietärer Gemini-Familie. Diese Abhängigkeit sowie eine gewisse Undurchsichtigkeit in der Post-Training-Methodik schränken die vollständige Reproduzierbarkeit durch die breitere KI-Forschungsgemeinschaft ein.
Demokratisierung der KI-Entwicklung
Die Veröffentlichung stellt einen bedeutenden Schritt dar, um fortschrittliche KI-Funktionen einem breiteren Spektrum von Entwicklern, Forschern und Enthusiasten zugänglich zu machen. Durch die Ermöglichung der lokalen Bereitstellung auf gängiger Hardware reduzieren Gemma 3 QAT-Modelle die Eintrittsbarrieren sowohl in Bezug auf Kosten als auch auf technische Anforderungen.
"Es geht um mehr als nur technische Fähigkeiten", reflektiert Chen, die Entwicklerin aus Brooklyn. "Es geht darum, wer mit diesen Technologien innovativ sein kann. Wenn leistungsstarke KI lokal auf Endverbraucherhardware läuft, öffnet dies Einzelpersonen und kleinen Teams Türen, die sich keine spezialisierte Infrastruktur leisten konnten."
Da KI zunehmend verschiedene Aspekte der Technologieentwicklung beeinflusst, könnte die Fähigkeit, hochentwickelte Modelle lokal auszuführen, für Innovationen außerhalb der großen Technologieunternehmen transformativ sein. Googles Ansatz mit Gemma 3 QAT deutet auf eine Zukunft hin, in der modernste KI zu einem demokratisierten Werkzeug und nicht zu einer zentralisierten Ressource wird.
Ob sich diese Vision vollständig verwirklicht, hängt davon ab, wie sich die Technologie entwickelt und wie die breitere Entwicklergemeinschaft diese Fähigkeiten annimmt. Vorerst hat sich die Kluft zwischen hochmoderner KI-Forschung und praktischer Bereitstellung jedoch deutlich verringert – eine Entwicklung mit potenziell weitreichenden Auswirkungen auf die Zukunft der KI-Zugänglichkeit.